Main search form
From the dictionary's main page you can run a configurable search using the following fields:
-
Coptic word - enter Coptic text in utf-8 characters. You can also use regular expression wildcards:
- Words starting in some prefix: ⲙⲛⲧ.*
- Words ending in some suffix: .*ϩⲏⲧ
- Wildcard in middle: ⲥ.ⲧⲙ
- Optional character: ⲥⲱⲧⲉ?ⲙ
- For complete documentation on regular expressions see: http://www.regular-expressions.info/
- Dialect - select one of the dialect sigla or use any for any dialect
- Scriptorium Tag - part of speech tag to limit the search by, based on the inventory described here
- Search in definitions - you can search within definitions in either English, French or German, or in any language. Searches can be restricted to exact sequences of words within definitions, or else to definitions containing all of the entered words in any order.
Quick search bar
You can quickly search for words without returning to the main search page by using the quick search bar at the top. You can enter:
- A Coptic word or regular expression - this will search for your word in any dialect (for regular expression search see above)
- English/French/German words - this will search for definitions containing all of these words in some language
- A combination of Coptic and definition words - searches for entries matching both, in any dialect and definition language
Frequencies and collocations
The Coptic Dictionary Online is linked to Coptic Scriptorium corpora. Users can search for attestations of words, get frequencies and rank information or browse collocations of words using the following icons on each entry's page:
 - click on this icon next to a word form to search for it in Coptic Scriptorium corpora (you will be taken to ANNIS, the project's search interface)
- click on this icon next to a word form to search for it in Coptic Scriptorium corpora (you will be taken to ANNIS, the project's search interface)- - pass over this icon to show frequencies and ranks for each word. For example, you can compare which is more frequent and how much: ⲉ or ⲛ?
- - if available, this icon shows collocations, words that cooccur with this word form much more often than expected by chance
Note: frequencies in the dictionary are cached and updated periodically. Numbers in ANNIS searches may differ slightly in some cases due to updates and/or slight differences in handling duplicate texts.
Phrase network graph
For entries with sufficient attestations in our corpora, you may see a phrase network graph thumbnail displayed as follows:
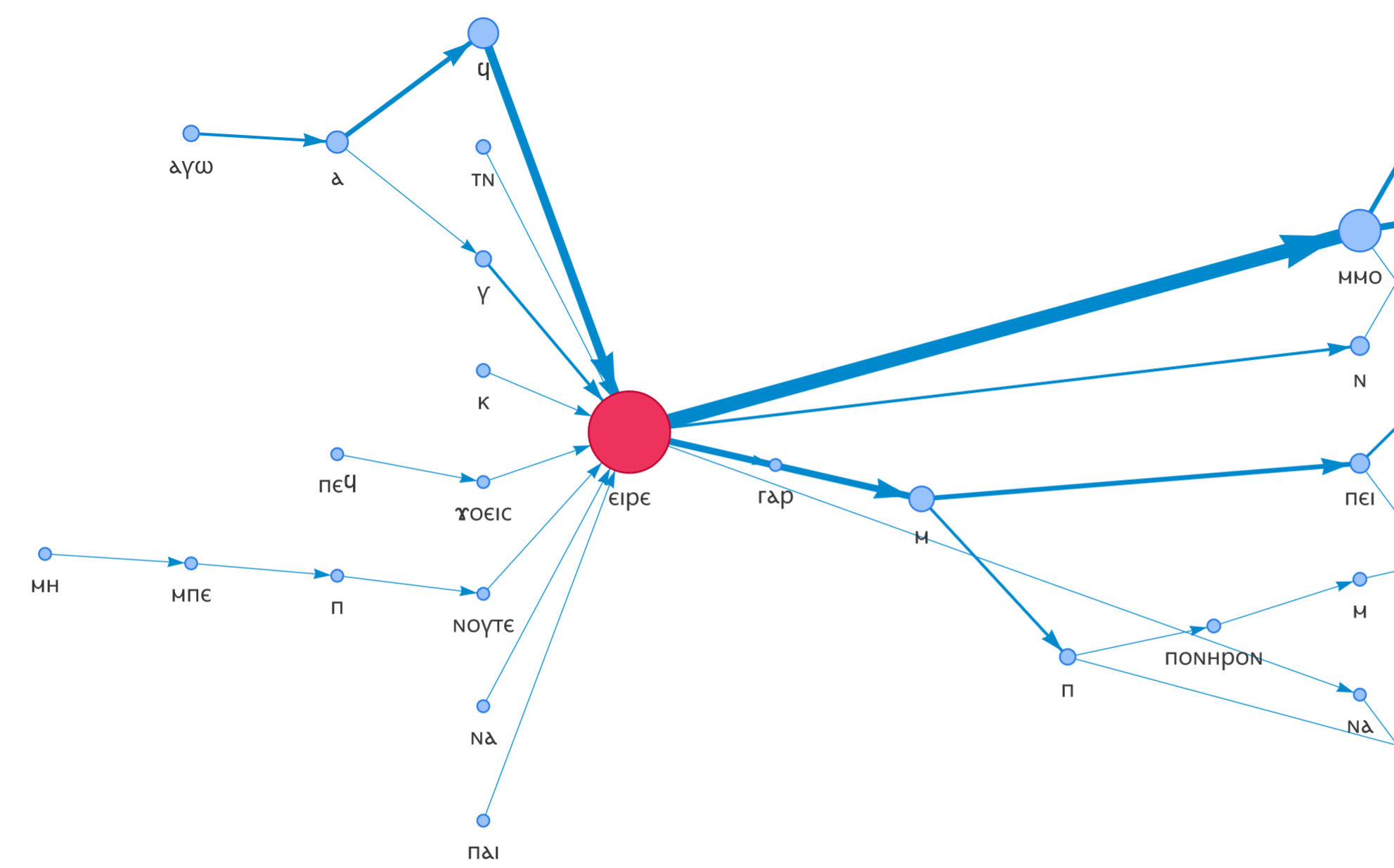
Clicking on this will take you to a phrase network graph like the one below, showing typical sequences of words involving this entry. The network shows a diagram of up to 20 most common phrases headed by the head word, truncated to 8 words at most for readability. Nodes and transitions are sized proportionally to how often they are attested in Coptic Scriptorium data. Correspondences between nodes in different phrases are computed using dependency parses based on the Coptic Universal Dependency Treebank.
Disclaimer: some errors due to automatic Natural Language Processing may be included in these graphs, which are provided as an assistive tool only.
Example usages
If available, each entry will also provide some automatically extracted examples of the entry, including examples of inflected forms of the same lemma, as shown below. As with network graphs, this functionality depends on automatic analysis and may occasionally contain errors - we welcome reports on incorrect examples at our GitHub repository.

For each example, you can also see the text from which it is extracted, and click on the URN link to see the entire text for more context.
Import of data into spreadsheet
You can import lemma entry data into a Google spreadsheet by copying formulas like the ones below into a cell of an empty spreadsheet.
| =IMPORTHTML("http://www.coptic-dictionary.org/entry.py?tla=C195"; "table"; 1) | table of forms (table 1) |
| =IMPORTHTML("http://www.coptic-dictionary.org/entry.py?tla=C3093"; "table"; 3) | table of senses (table 3) |
| =IMPORTHTML("http://www.coptic-dictionary.org/entry.py?tla=C3093"; "table"; 4) | table of related entries (table 4) |
| =IMPORTHTML("http://www.coptic-dictionary.org/results.py?coptic=ⲣⲱⲙⲉ&dialect=any&pos=any&definition=&def_search_type=exact+sequence&lang=any"; "table"; 1) | search reply |
| =IMPORTHTML("http://www.coptic-dictionary.org/results.py?coptic=ⲣⲱⲙⲉ"; "table"; 1) | search reply, simple |
Example:
